

The recent release of Nuke 13 brought along the update from Python 2 to Python 3. After all, Python 2 has been officially dead since January 2020, and Python 3 has been around since 2008, so that update was due.
Python 3 comes with quite a few improvements and a few changes that can easily break scripts written for Python 2.
There are plenty of resources online explaining how to port older code to Py3 (for example: https://docs.python.org/3/howto/pyporting.html, https://docs.python.org/3/library/2to3.html, https://www.pythonconverter.com/), but I figured I would do a little write-up of the most common errors I encounter as I upgrade my own tools to be Nuke 13 compatible.
The first time you try to open Nuke 13, you are likely to be greeted by this friendly message:
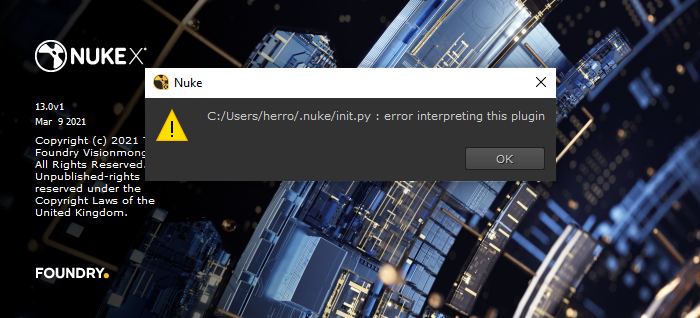
If you click OK, everything goes away, and you have no idea what is wrong.
When you open Nuke, a Terminal Window also opens, and this is where you’ll be looking for useful information:
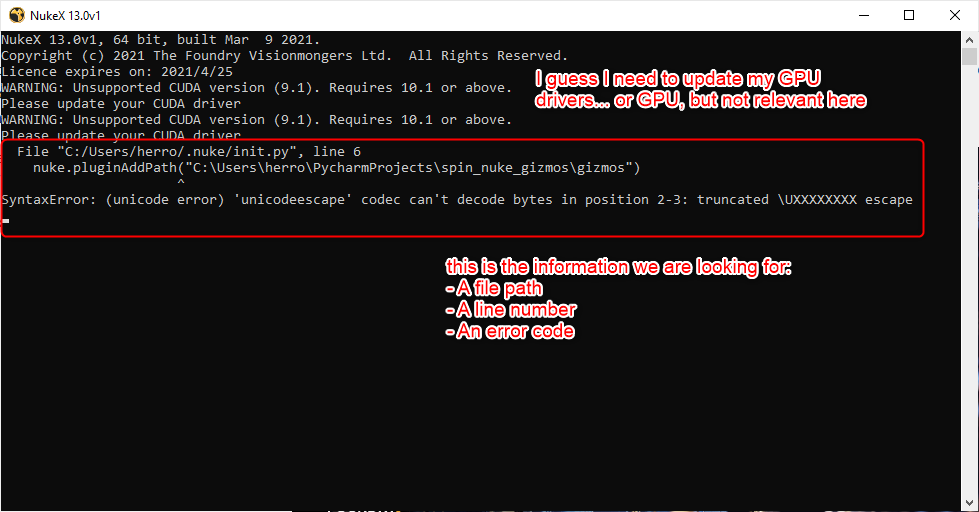
The content of my terminal upon my first launch of Nuke 13
In this case, this was mostly a bad line of code. For Windows path, it’s recommended to use \\ instead of \ as backslashes are a special character and are used to escape other characters. This could have been a disaster in Python 2 as well, but somehow it worked. After opening the file and doubling my slashes, I can now retry to open nuke:

Oh no! Another error! We really didn’t expect that to happen, did we?
We could now open that file, fix the error, launch Nuke, find the next error, open, fix, launch, find, etc… Depending on how many packages you have installed, it could take a while.
Using Pycharm for help
As often, when working with Python, a good IDE can help.
In Pycharm, you can enable code compatibility inspection:
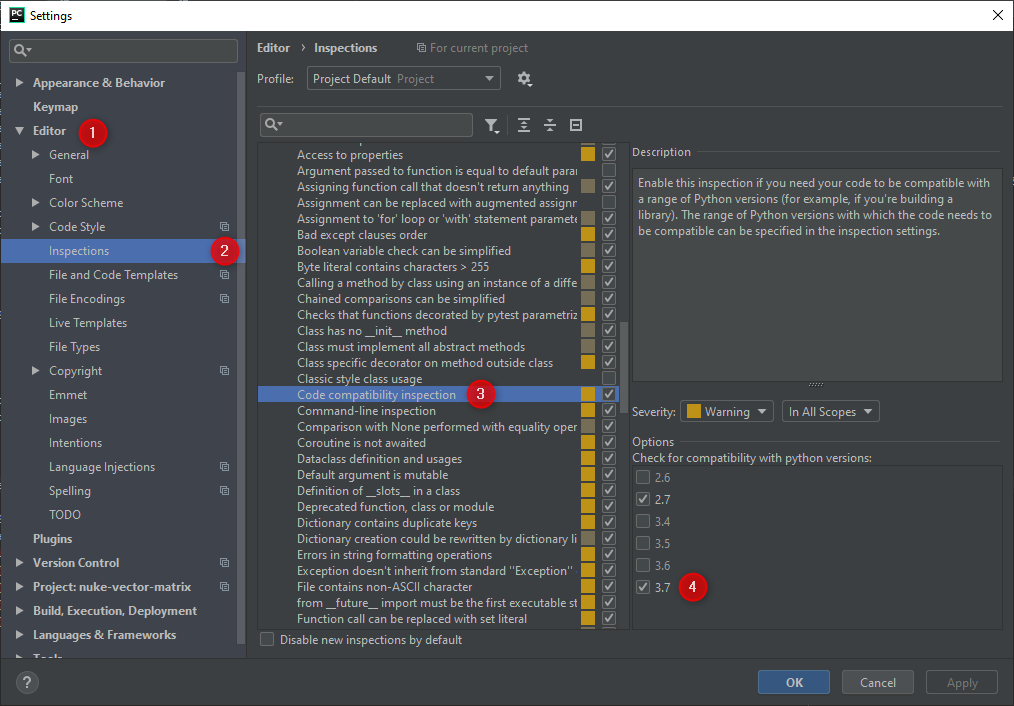
This will now highlight code that is not compatible with both Python 2.7 and 3.7 (The version targeted by the VFX reference platform for 2020).
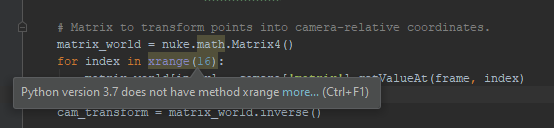
This is great while writing code, as it will highlight incompatible code right away. Converting old codebases could still be tedious, so let’s look at a more efficient option:
Let’s try to use the code inspection tool of PyCharm:
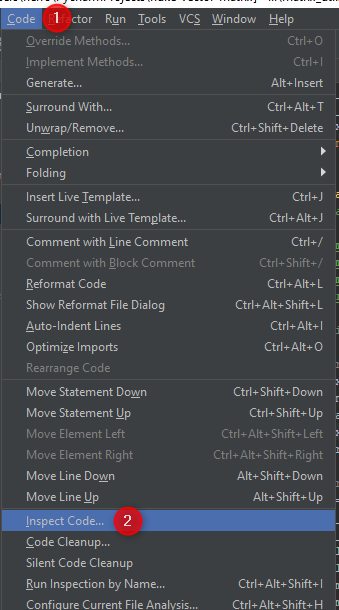
We want to inspect the whole project (well, I do, but you do you). I also want to focus on Python3 errors, none of the other warnings that may show up. We’ll make a new inspection profile (2) in the next step.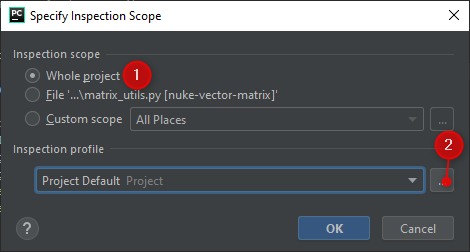
At the top, duplicate your current profile, rename it, then modify it as desired.
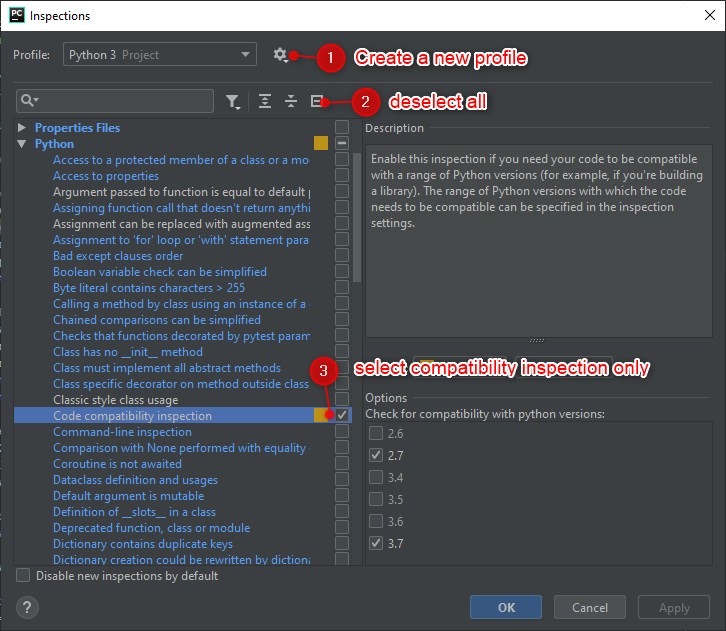
After you click OK, it brings you back to the Inspection Dialog, where you can hit OK to run the inspection.
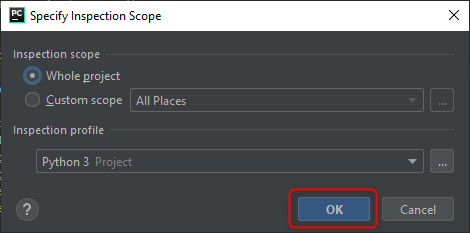
The results will now show up, sometimes with tips on how to solve the issue.
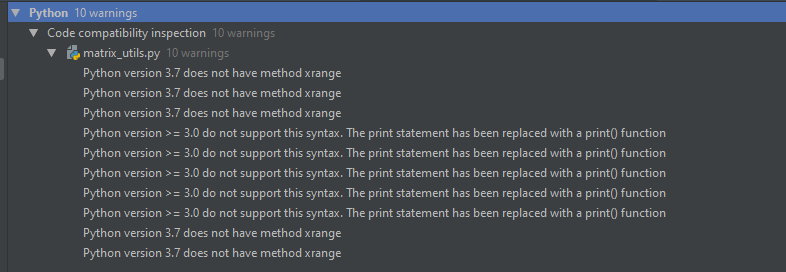
Errors encountered
I can’t list all errors possible, but I’ll list below the errors I run into as I fix my own projects. Feel free to add more in the comments or ask questions here or on the Nuke forum. As more errors get discovered, I’ll update this list.
print statement
By far, the most common error you will run into is about the print statement that was replaced by a print function. What does it mean?
# print statement, Python 2.7:
print "hello world!"
# print function, Python 3.x:
print("hello world!")
It’s not a huge change, but print statements are so commonly used that this will possibly be annoying.
Worse, Python 2.7 does not by default support the print function, so if we were to replace print statements with print functions, it could change the code’s meaning on older versions of Nuke.
It turns out we don’t really care. Typing print(“hello world!”) would print a Tuple containing the string “Hello World!” and that’s totally fine by me.
Also, I find that many print statements aren’t really that useful and were likely added while coding as a way to debug and keep track of things, so the other solution is to remove the line entirely.
TLDR: Either add parentheses around the stuff to print or delete the whole line.
xrange function
In Python 2, while range() is working, it was somewhat inefficient, and when I was learning Python a decade ago, xrange() was recommended, as it was more efficient. I have used xrange quite extensively.
In Python 3, they put the optimizations of xrange and put them directly in range, then removed xrange. The fix is to replace every use of xrange() by range(). It will still work in py2, albeit slightly less efficiently.
basestring/unicode classes
Python 2 has a few object types to deal with words: basestrings, strings, Unicode. It also stored binary data as strings. Python 3 threw away the differences and now has a single string class, plus a new binary class (bytes). Believe it or not, dealing with different types of strings, particularly mixed-use of Unicode and strings, was one thing that gave me the biggest headaches in Python 2, so this is a change I welcome with open arms.
I’ve seen all sorts of weird things done around these issues, so I don’t have a recipe on how to fix this. If migrating from 2 > 3 permanently, usually we can remove weird workarounds.
A common pattern I have noticed is:
def some_function(argument):
""" This function can accept either a string or a list as argument """
if isinstance(argument, basestring):
argument = [argument]
for something in argument:
do_it()
In Python 2, the example above would catch any subclass of basestring (str, unicode) and convert them to a list. (Note that it doesn’t check what is in the list if you pass a list already, but that’s another story). This would error in Py3, as there is no such thing as basestring. You could replace basestring with str, but in py2, this might result in unexpected behaviour if somehow a unicode is passed as the argument. I prefer to think of it slightly differently:
def some_function(argument):
""" This function can accept either a string or a list as argument """
if not isinstance(argument, list):
argument = [argument]
for something in argument:
do_it()
implicit relative imports
This will only impact those of you who have started writing multi-file python packages.
Consider the following imaginary package, which contains a generic module defining all possible body parts that a creature might have, and so far our only created creature: a unicorn.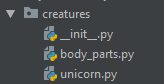
Our unicorn imports may look something like this in python 2:
from body_parts import Head, Leg, Torso, Tail, Horn
This is a relative import, because our package is named creatures, and we import a submodule of creatures inside another submodule of creatures, by the submodule name only. It’s also implicit because nothing in the code indicates whether it is relative or absolute. Imagine we now had another package in our python path, itself called body_parts:
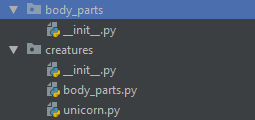 Suddenly, our import statement is ambiguous. Are we referring to body_parts the package or body_parts the sister module?
Suddenly, our import statement is ambiguous. Are we referring to body_parts the package or body_parts the sister module?
To avoid confusion, Python 3 doesn’t allow implicit relative imports and would fail in both cases. In the first case (without the body_parts package), it would error because it would be looking for a package named body_parts, and not find one. In the second case, it would find our other body_parts package, which happens to not have all these classes we’re looking for defined.
The solution would be to either do an absolute import (this is what I tend to do):
from creatures.body_parts import Head, Leg, Torso, Tail, Horn
or do an explicit relative import (you make it explicit by using the dot notation):
from .body_parts import Head, Leg, Torso, Tail, Horn
integer divisions
This one might not cause an error on load but could cause errors during execution.
In Python 2, dividing an integer by another integer results in an integer:
>>> # Python 2 >>> 5/2 2
In Python 3, dividing an integer by another integer results in a float:
>>> # Python 3 >>> 5/2 2.5
A new integer division operator was added:
>>> # Python 3 >>> 5//2 2
Sadly this is likely going to affect quite a few scripts that performed node placement, as it was a fairly common pattern to divide the size of the node by 2 to get its center, and setXYpos methods error if you give them float values. This is what is breaking nukescripts/psd.py, lines 81 and 135 for example. Hope the foundry fixes that one.
your error here!
if you run into an error, feel free to post it in the comments and I’ll be adding them in here as we go
this is super helpful Erwan, thanks
as a request, could you also post some tips on pyside – pyside2 …
Hi Tony. I could, thought that was back in Nuke 11. That’s almost an article onto itself, but maybe I’ll add it as a section here.
Do you have some example code that you’re struggling to convert that you would like to send me?
Great article. Thanks! Have yet to transition to 13 but this will help for sure.
NukeX 13.0v1, 64 bit, built Mar 9 2021.
Copyright (c) 2021 The Foundry Visionmongers Ltd. All Rights Reserved.
File “C:/Users/ASUS/.nuke/menu.py”, line 630
nuke.knobDefault(‘Shuffle.note_font_size’, ’15’)
^
SyntaxError: invalid syntax
From the line you copied it’s not obvious exactly what the error is. It could likely be related to the previous line missing a bracket or something. Feel free to post a few more lines of your code or send me the file by email or something.
Should all py3 code be accesible by py2? Probably not… Will we need to add something like an if-statement for either py3 and py2 and basically add the whole function again with its conversions? How could we, as a community and user base, make this as fluent as possible?
I found that most fixes from 2 to 3 happened to be compatible with both, as python 2.7 was released with this issue in mind already. There’s a few things that could be handled with the __future__ module, but I found that’s not always installed by default.
I would be of the opinion of dropping support for 2, but I know it’s gonna take a couple of years before most people actually switch to nuke 13. You shouldn’t have to write entirely different functions though.
it will be great if you make a video as a tutorial, i tried a few times but it didnt work for me, i never worked with Python before, so step by step tutorial would be very helpful for people like me.
thanks for the post 🙂
Hello. I’m not really setup to make video tutorials, and these take a bit more time than I have at the moment to produce. I’ve noticed that usually when I post a tutorial someone makes a video about it a few weeks later.
Hello Erwan, Thanks for the great article, it was really helpful and informative. I added some lines of additional code to my init.py in the .nuke folder in order to have my comp artist continue working in nuke 12 and test 13 without the crashes as I experiment porting all the tools we need. The goal is to have the tools packs separated for both versions and have nuke load what it needs based on the version you are opening. Thanks again for all the great info and keep being awesome.
—————————————————————————————————
import nuke
if str(nuke.NUKE_VERSION_MAJOR)==’12’:
nuke.pluginAddPath(“./Tools/12/your ToolsGizmoPack folder”)
if str(nuke.NUKE_VERSION_MAJOR)==’13’:
nuke.pluginAddPath(“./Tools/13/your ToolsGizmoPack folder”)
That is one way, the problem will be when 14 comes out you will need to add a line again, or modify. That’s fine, but if you need something a bit more future proof and scalable you could look into controlling plugins via environment variables.
Thank Erwan for your reply, and I agree with you. Definitely will set this as soon as I get a breather. I appreciate the info.
Thanks for this!
Trying to get the Nuke Studio/Hiero “Thumbnail Exporter” from dotStudo (https://github.com/antiero/dotStudio) working with Nuke 13. Fixed the print() functions. Also found some unicode() functions that are no longer in 3 and replaced with str() per some random stack overflow comment.
Seems to be some larger issue though. Perhaps related to relative imports? Not expecting personalized tech support or anything, but curious if you have any insights. Here the error in the script editor when Nuke Studio launches:
ERROR 19:48:40.747:Hiero(78089): Plugin /Users/jeremy/.nuke/Python/Startup/thumbnail_exporter/__init__.py could not be loaded: No module named ‘ThumbnailExportTask’
Traceback (most recent call last):
File “/Applications/Nuke13.0v1/Nuke13.0v1.app/Contents/Resources/pythonextensions/site-packages/hiero/core/find_plugins.py”, line 53, in loadPluginsFromFolder
module = __import__( packageName )
File “/Users/jeremy/.nuke/Python/Startup/thumbnail_exporter/__init__.py”, line 1, in
import ThumbnailExportTask
ModuleNotFoundError: No module named ‘ThumbnailExportTask’
It does look like that __init__ file does relative imports.
If you change that import to
from dot_studio.thumbnail_exporter import ThumbnailExportTaskit should be okay. Probably have to fix a few of these.I just installed Nuke 13 and after this whole fiasco with the Python 3 transition, I’ll just go back to Nuke 12…
Thanks once again Erwna 🙂
Hey Erwan!
Thank you very much for this guide, quite helpful!
Hey Erwan! This seems super useful, only downside I can find so far as we consider using pycharm – it doesn’t support UNC paths in the IDE itself for projects? I know you can map them to a drive letter, but that seems tedious and annoying for every project etc you’d wanna setup. Curious how you’re handling that/what your setup is. Cheers!
I never had to deal with UNC paths until very recently. Even now that I’m in an environment with UNC paths, my dev area is in an area that has a mapped drive, so it hasn’t been too much of a problem. Pycharm definitely likes it better when working with local files, it can slow down quite a bit when using with network projects.
I’d also be curious to know if you have any helpful tips for setting up PyCharm to play nicely with Nuke – We also don’t have any of the larger scale things like a dev server or git setup at the moment, so that seems to be one of the big things I’m bumping up against doing research on how to set it up. I did already find your answer on the foundry’s site to someone else on how to get the environment variables for the interpreter in pycharm which is great, now there’s tab autocomplete at least 😀
Also worth an ask – I’m guessing there’s no easy way to do step-through for things that are intended to run inside nuke on node selections or user input with panels etc?
Can you precise exactly how it’s not playing nice with Nuke? I might have ideas if you have a specific example but I can’t think of anything right now.
When you talk about step-through, do you mean like the debugger (execute line by line) or something else? The debugger is only in Pycharm pro, and worth the update by itself in my opinion.
That’s good to know about the upgrade for being able to step through, I hadn’t tried it yet, I’m still sort of getting my bearings in PyCharm honestly.
I’ve been following this on how to attach the debugger to a nuke process: https://github.com/cglukas/nuke-pycharm/blob/main/tips/attached-debugging.md and then running import and reload functions inside nuke’s script editor.
Which seems to work, but i’ve noticed that if it errors then it’ll crash nuke, unfortunately. Which is what I’d say is the biggest “not playing nice” with trying to use PyCharm to debug at the moment. This may be a side effect of not using it as intended though to try to debug code that operates based on selectedNodes() etc.
I haven’t tried that method for debugging, always pycharm pro’s remote debugger, which doesn’t crash nuke on errors, but has some other possibly annoying things, like having to run some python snippet to connect to the debugger which might mean it’s sometimes tricky to debug production code.